很多初级甚至有丰富开发经验的开发者都可能会遇到乱码的问题,对深入理解字符编码的人来说,问题很容易解决。但如果你对字符编码一知半解,这些问题可能会让你抓狂。对一名开发者来讲,不管你使用什么语言,在什么平台上开发,字符编码都是需要掌握的基本技能之一。
我们都知道,计算机只能处理0和1,为了让计算机能够处理我们的信息,就需要对信息进行编码。信息编码是一个很大的主题,本文只涉及计算机字符的编码,包括ASCII、Unicode、UTF-8、UTF-16、UCS-2。
ASCII
对于ASCII大家都比较熟悉,由于当时硬件和计算资源都很匮乏,ASCII只使用了前7位,可以表示128个字符,如0是48(二进制0011 0000),a是97(二进制0110 0001)。
对于英语来说,128个符号已经够用了,但对其它语言来说,128个符号是不够的,当计算机传入欧洲后,有些欧洲国家利用闲置的最高位编入新的符号,这样就可以最多表示256个符号。IBM当时针对不同语言,在(128-255)区间内OEM了不同的编码方式,这也造成了同一个编码可能表示不同的符号。
对于亚洲国家就更惨了,汉字就多达10万左右,一个字节根本表示不了这么多符号,于是就有了两个字符表示一个符号,这样理论上最多可表示256 x 256 = 65535个字符,这对表示常用的汉字就够用了。
鉴于以上各种编码方式的混乱,于是出现了Unicode。
Unicode
Unicode编码就如其名字一样,旨在为全世界所有的符号进行编码,且每个符号的编码都不一样。其编码空间能容纳上百万个字符。如用U+0030表示0,用U+4E2D表示中。需要注意的是:Unicode只是一个字符集,它定义了每个符号的二进制代码,它并没有规定这些二进制代码在计算机中如何存储。更多关于Unicode的知识请参考unicode.org或维基百科。
仍然以中为例,其Unicode的十六进制表示为4E2D,对应的二进制为100111000101101,足足有15位,所以至少需要2个字符来存储。对于更大编码的字符,可能需要3个甚至4个字符来存储。这里有两个问题必须考虑:
1. 如果用足够容纳所有字符的字节,比如4个字节来存储,这样对英语语种来说,以前每个字母只需要1个字节,现在却需要4个字节来存储,而且前面三个字节全是0,这对计算机存储资源是极大的浪费!
2. 如果采用变长的字节来存储,比如对ASCII字符仍然采用1个字符,对汉字采用2个或3个字节,那么计算机如何区分1个字节表示一个字符或2个字节甚至3个字节表示一个字符呢?
于是各种编码标准应用而生,其中应用比较广泛的是UTF-8。
UTF-8
什么是UTF-8?它跟Unicode是什么关系?
UTF是 Unicode/UCS Transformation Format 的首字母缩写,即把Unicode字符转换为某种格式之意。UTF-8只是Unicode字符集的一种编码实现。其它实现还有UTF-16和UTF-32等。UTF-8最大的特点是它是一种变长编码方式,它可以用1~4个字节表示一个字符,其编码规则也比较简单,简述为以下两条规则:
1. 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode 码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2. 对于n个字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结UTF-8的编码规则,其中x表可编码的位:
| Unicode符号范围(十六进制) | UTF-8编码(二进制) |
|---|---|
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
我们仍然以以中为例,演示如何进行UTF-8编码:
中的Unicode为4E2D(100111000101101),其Unicode在第三行0000 0800 - 0000 FFFF之间,于是其对应的二进制格式应该为1110xxxx 10xxxxxx 10xxxxxx。接下来,只需要把中的二进制位从最低位开始,依次填入x中即可,最终得到中的UTF-8编码为11100100 10111000 10101101,转化为十六进制为E4B8AD。
UCS2 & UTF-16
Unicode的编码空间从U+0000到U+10FFFF,共有1,112,064个码位(code point)可用来映射字符。Unicode的编码空间可以划分为17个平面(plane),每个平面包含65,536(2的16次方)个码位。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0x00到0x10,共计17个平面。第一个平面称为基本多语言平面(Basic Multilingual Plane, BMP),或称第零平面(Plane 0)。其他平面称为辅助平面(Supplementary Planes)。基本多语言平面内,从U+D800到U+DFFF之间的码位区块是永久保留不映射到Unicode字符。UTF-16就利用保留下来的0xD800 - 0xDFFF区段的码位来对辅助平面的字符的码位进行编码。
UCS即通用字符集(Universal Character Set, UCS),在国际标准ISO10646中定义,和Unicode一样,它只定义了每个符号的二进制代码,位并没有规定这些二进制代码在计算机中如何存储。UCS-2表示用两个字节来存储。
UCS-2可以看成是UTF-16的子集。在没有辅助平面字符前,UCS-2和UTF-16所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。对于UCS-2编码,其实是暗指它不能支持在UTF-16中超过2字节的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码。
具体关于UTF-16的编码解码规则请参考RFC文档。
Windows对字符的处理
记事本程序
我们平时用Window记事本程序notepad.exe保存文件时可能没有注意到,当我们选择另存为(Save As…)时,可以指定编码方式:
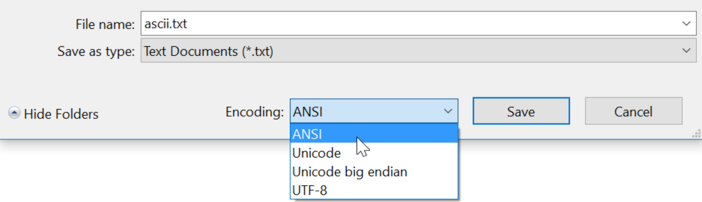
可以看到notepad.exe程序为我们提供了4种类型的编码方式:ANSI、Unicode、Unicode big endian和UTF-8。如果我们新建4个文本文件,按照4种编码方式分另在每个文本中都保存一个中字,再用WinHex软件打开看看其二进制内容如下:
| 编码方式 | 十六进制 |
|---|---|
| ANSI | D6 D0 |
| Unicode | FF FE 2D 4E |
| Unicode big endian | FE FF 4E 2D |
| UTF-8 | EF BB BF E4 B8 AD |
- ANSI是默认的编码方式。这个跟具体的操作系统语言选择有关,对于英文文件是ASCII编码,对于简体中文文件是GB2312编码。
- Unicode编码是指使用的UCS-2编码方式,关于UCS-2上面已经讲过,即直接用两个字节存入字符的Unicode码,这个选项用的 little endian 格式。
- Unicode big endian编码与上一个选项相对应。
- UTF-8编码,上面已经介绍过了。
细心的读者可能已经观察到,对于Unicode和Unicode big endian有两个地方不同:
- Unicode和Unicode big endian每两个字节的存储顺序相反,如
FF FE 2D 4E和FE FF 4E 2D- 文件开头都加了一个
FEFF(Unicode顺序相反为FFFE)
对于第一个问题,涉及到大小端序,它是CPU寻址的不同方式,简单地说就是:
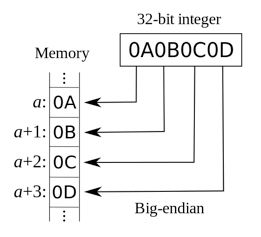
大端序:最高位字节存储在最低位内存地址处,次高位字节存储在次低位内存地址中,以此类推。
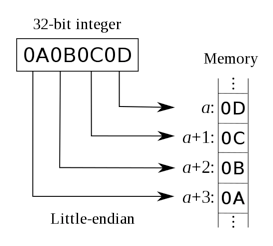
小端序:最低位字节存储在最低的内存地址处,次低位字节存储在次低位内存地址处,以此类推。
以字节一个32位(4字节)的整数0x0A0B0C0D为例,以大端序方式存储为:
以小端序方式存储为:
对于第二个问题是Unicode规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做零宽度非换行空格(zero width no-break space),也称为BOM(byte-order mark),用FEFF表示,这正好是两个字节,按照大小端序的定义,文件开头存储的是FEFF表示大端序,存储的是FFFE表示小端序。
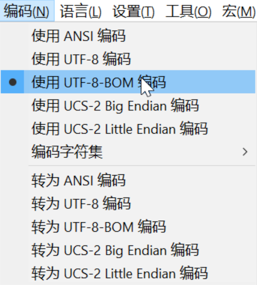
而对于UTF-8,其字节顺序是不变的,不存在大小端序的问题。如果以UTF-8编码的文件开头有BOM,按照UTF-8编码规则,FEFF被编码为EFBBBF,这个文件被称为使用UTF-8-BOM编码;如果文件开头不包含BOM,我们通常说这个文件为使用UTF-8编码。我们使用notepad++等文本编辑器时,在编码中可以看到:
VC++对字符的处理
Windows操作系统内核中的字符表示为UTF-16小端序,可以正确处理、显示以4字节存储的字符。但是Windows API实际上仅能正确处理UCS-2字符,即仅以2字节存储的,码位小于U+FFFF的Unicode字符。其根源是Microsoft C++语言把wchar_t数据类型定义为16比特的unsigned short,这就与一个wchar_t型变量对应一个宽字符,可以存储一个Unicode字符的规定相矛盾。
除了上节说的用记事本进行字符的编码转化外,Windows提供了MultiByteToWideChar和WideCharToMultiByte两个API用于多字节与宽字节的两互转化。关于这两个API的具体使用方式,可以参考MSDN。对于VC++,这里简单说一下平时使用比较多的两种转化,仍然以中为例,上面已经提到,在简体中文系统里面,ANSI实际上是按GB2312进行编码,其编码为D6D0,UTF-8编码为E4B8AD,转化成Unicode应该为4E2D:
- ANSI转Unicode
1 | BYTE asni[] = { 0xD6, 0xD0 }; |
- UTF-8转Unicode
1 | BYTE utf8[] = { 0xE4, 0xB8, 0xAD }; |
注:需要说明的上述代码跟平台相关,最后对结果之所以采用这种断言方式,_ASSERT(unicode[0] == 0x2D && unicode[1] == 0x4E);是因为Windows操作系统默认采用小端序,如果你忘记了什么是小端序,请回到上节温习一下。
对于Unicode转ANSI和Unicode转UTF-8只是上面的逆过程,使用 WideCharToMultiByte,修改相应参数即可,在此不在累赘。
总结
- Unicode只是一个字符集,它定义了每个符号的二进制代码,它并没有规定这些二进制代码在计算机中如何存储;
- UTF-8只是Unicode字符集的一种编码实现方式之一。其它实现方式还有UTF-16和UTF-32等;
- 在没有辅助平面字符前,UCS-2和UTF-16所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。对于UCS-2编码,其实是暗指它不能支持在UTF-16中超过2字节的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码;
- 大端序是指最高位字节存储在最低位内存地址处,次高位字节存储在次低位内存地址中,以此类推;小端序是指最低位字节存储在最低的内存地址处,次低位字节存储在次低位内存地址处,以此类推;
参考资料
[1] rfc3629
[2] rfc2781
[3] 字符编码笔记:ASCII,Unicode 和 UTF-8
[4] The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
[7] Endianness