之前虽然看过很多分布式系统相关的书籍、论文和一些开源项目,但很少自己动手去实现。理论跟工程实现通常有非常大的差别,一个看似很简单的协议,在工程实现上可能非常困难。6.824是MIT开设的分布式系统课程,非常系统的讲解了分布式系统的主流技术,同时将理论和实践相结合,是一个非常好的课程。
本文是笔者在学习6.824 lec1课程的一些总结和思考,算是一个学习笔记。在看这篇文章之前,我希望读者先提前阅读以下资料:
- MapReduce: Simplified Data Processing on Large Clusters
- 6.824 2022 Lecture 1: Introduction and video
- 6.824 Lab 1: MapReduce Guidance
本文主要分三个部分,第一部分概述性的介绍mapreduce的原理;第二部分概述性的介绍mapreduce的实现;第三部分介绍工程实现上需要注意的一些问题,完整代码实现参考github。
MapReduce原理概述
学习一门技术,最好先从了解这项技术诞生的背景开始。MapReduce是Google在2004年提出的一项技术,用于大规模集群中处理大规模的数据集。在04年之前,Google内部就有很多用于处理各种大数据的专用系统,比如有处理爬取网页数据的系统,处理web请求日志的系统等等。经过对各个数据处理系统的分析,发现可以这些系统的数据处理过程抽象为统一的编程模型,这就是MapReduce。
MapReduce编程模型是非常简洁的,整个数据处理过程是:输入为<key,value>数据集,输出也为<key,value>数据集,其中,在处理过程中,会调用用户实现的Map和Reduce函数,Map和Reduce的接口如下:
1 | Map (k1, v1) -> list(k2, v2) |
Map函数
Map函数对输入的<k1,v1>数据集处理后,会生成中间的<k2,v2>数据集,MapReduce框架将所有key为I的中间数据聚合后将<k2, list(v2)>做为Reduce函数的输入。
Reduce函数
Reduce函数将map函数处理后的<k2, list(v2)>作为输入,Reduce函数处理后,生成一个更小的数据集输出。Reduce中list(v2)采用迭代器的方式获取,以应对v2非常大,超过单机内存限制的问题。
词频统计示例
1 | Input1 -> Map -> a,1 b,1 |
1、将输入分割为M个文件,比如上图中的每个input,可以理解为一个文件
2、MapReduce对每个文件调用Map函数,Map函数的输入<k1,v1>对可以理解为<文件名,文件内容>,Map函数的输出为<k2,v2>数据集,其中key为单词,value为1。比如Input1文件中有两个单词a和b,输出为<a,1>和<b,1>
3、当所有Map处理完毕后,MR将所有中间<k2,v2>数据集聚合,并将聚合后的<k2, list(v2)>给到Reduce作为输入。比如将key为a的数据集聚合为<a, [1,1]>, key为b的聚合为<b, [1,1]>, key为c的聚合为<c, [1]>
4、Reduce根据对输入<k2, list(v2)>处理后,生成<k2, v3>,如对<a, [1,1]>处理后,生成<a, len([1,1])>,即<a, 2>
Map/Reduce词频统计函数的伪代码:
1 | Map(k, v) |
MapReduce实现概述
MapReduce的整体执行流程如下:
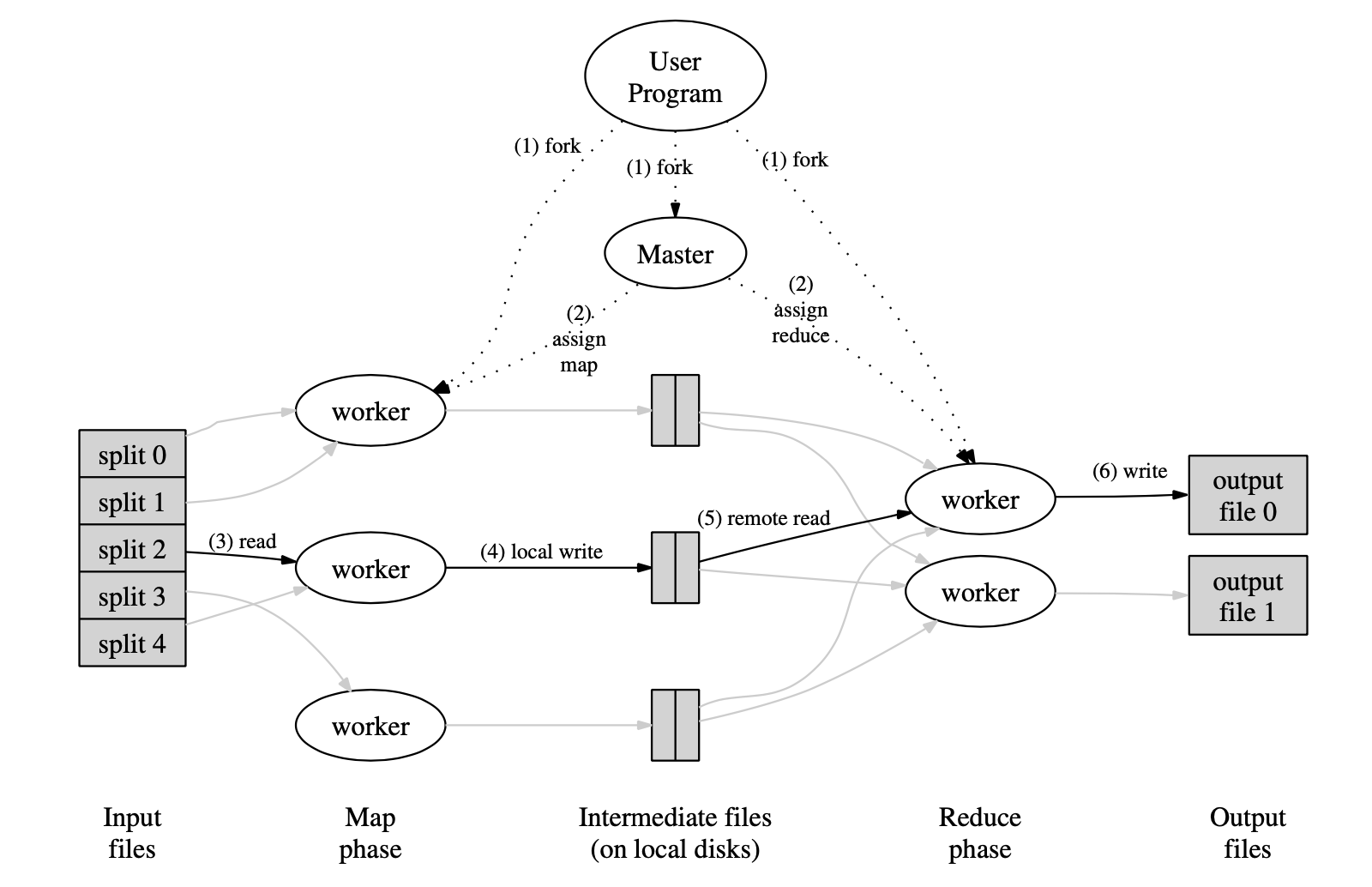
1、MapReduce将输入分片成M个小文件,对于Google内部,文件是存在另一个分布式文件系统GFS上,本身就已经分片好了,在本实验中,可以理解为一个文件就是一个分片。然后启动一个master进程和多个worker进程。在实验中master称为coornidator。
2、master负责给worker分配任务,一共有M个map任务和R个Reduce任务,其中M和R都是作为任务参数输入的。master会选择空闲的worker,给他们分配map任务或reduce任务。在本次实验中是采用worker主动询问的方式向coordinator获取任务,coordinator先分配map任务,当所有map任务都完成时,再分配reduce任务。
3、worker被分配到map任务后,将输入的分片文件读取,解析为<key, value>数据集,对每个<key, value>对,调用用户定义的Map函数。并将生成的中间结果<key, value>缓存到内存。
4、worker周期性的将内存中缓存的中间结果写入本地磁盘,并按用户定义的partion函数将key分片到R个桶中进行存储,完成后将结果汇报给master。仍以词频统计为例,例如R=3,调用partion函数,输出被hash到[0-3)中:
也就是说每个map任务会将中间结果写到这3个桶中(也就是三个中间文件),即所有partition(key)=0的<key,value>被分到0桶中,所有partition(key)=1的<key,value>会被分到1桶,所有partion(key)=2的<key,value>会被分到2桶,比如对于Input1,Map后生成了两个key a和b,如果partion后的值如下:
1 | 0 = partion(a) |
那么0桶的中间文件内容为<a, 1>,1桶的中间文件内容为<b, 1>
5、worker被分配到reduce任务后,master会告诉其桶为r的所有中间文件所处的位置。reduce任务将桶为r的所有中间文件内容读取至内存后,按key进行排序(如果数据量特别大,超时单机内存限制,还有进行外部排序),这样相同的key就会聚合在一起。
以词频统计为例,如果partion(a)=0,reduce任务被分配到处理r=0桶,则reduce任务需要读取所有Map任务生成到0桶的中间文件,即Input1中0桶的中间数据<a,1>和Input3中的0桶的中间数据<a,1>,排序聚合后生成<a, [1,1]>
6、reduce任务遍历指定桶中的所有数据,对于每一个唯一的中间key,将该key以及对应的中间数据values作为用户定义的Reduce函数的输入,reduce任务将key以及Reduce函数的输出<key, value>写入指定桶的最终输出文件中。
7、所有map任务以及reduce任务完成后,整个MapReduce计算完成。
工程实现上的一些问题
整个工程代码量几百行,6.824 Lab 1: MapReduce已经给了很好的引导,关于map和reduce的框架层实现,在mrsequential.go已经给出了,在此我并不想介绍所有工程实现的所有细节,以下列出一个关键点。
coordinator和worker的交互协议
在这个实验中,采用C/S架构,worker以询问的方式从coordinator获取任务,worker任务执行完成后,需要将结果汇报给coordinator。我将coordinator和worker的交互抽象为命令,其中命令协议如下:
1 | worker -> coordinator: <cmd, data> |
worker发起命令请求,请求内容为:命令名称(cmd)、请求数据(data)
coordinatior处理命令完成后,返回内容为:命令名称(cmd)、命令ID(cmd_id)和返回数据(data)
命令有两种:请求任务命令和汇报任务命令
请求任务命令
1 | worker -> coordinator: <CMD_FETCH_TASK, ""> |
为了解析处理的方便,所有任务都通过同一个结构TaskNode进行描述,结构定义如下:
1 | type TaskNode struct { |
对于任务类型,一共有4种:
1 | TASK_TYPE_MAP: map任务 |
汇报任务命令
汇报任务比较简单,使用task_id和task_type描述一个任务,交互协议如下:
1 | worker -> coordinator: <CMD_REPORT_TASK, cmd_id, {task_id, task_type}> |
worker优雅退出
当worker发起请求任务时,coordinator记录了所有map和worker任务的状态,当发现所有map和worker任务已经完成时,coordinator在请求任务命令中返回一个退出任务类型。worker收到退出任务后,退出worker。交互协议内容如下:
1 | worker -> coordinator: <CMD_FETCH_TASK, ""> |
coordinator并发操作对共享变量的访问
worker与coordinator交互时使用RPC或HTTP协议,coordinator在处理命令时是并发的,当在并发操作中对共享变量进行访问时,需要做一些保护机制。为了使编程更简单,在实现时,我采用了事件驱动机制,将所有命令抽象为事件,发送到事件队列中,并开启一个单独的线程用于消费事件。
由于所有共享变量均在同一个线程中访问,故并不需要对共享变量进行加锁保护。
事件数据结构定义
1 | // 事件请求 |
事件循环
1 | func (c *Coordinator) eventLoop() { |
发送事件到事件队列
1 | func (c *Coordinator) sendEvent(name string, data string) *EventResponse{ |
worker超时处理
coordinator在分配map或reduce任务给worker后,如果在一定时间内没有收到worker的汇报,需要将该任务重新分配给其它worker处理。在实现时,每次成功分配一个任务,就开启一个单独的线程,同时监控任务的汇报和任务超时。
- 如果收到worker的任务汇报通知,退出等待线程
- 如果超时,发送一个任务超时事件到事件中心,由事件超时任务处理器处理,处理器实现也比较简单,只需要将正在运行队列中的超时任务移除并重新加入到等待任务队列中
1 | func (c *Coordinator) asyncWaitTaskDone(task *TaskNode) { |
中间文件的原子性
在现实生产环境中,worker可能会随时crash掉,如果在生成部分中间文件时,worker crash掉,会产生很多可见的中间文件,为了保证生成中间文件的原子性,可以使用Go标准库中提供的ioutil.TempFile方法,先使用TempFile保存中间文件的数据,当所有中间文件生成后,再使用os.Rename对这些临时文件重命名。如map任务后生成中间文件:
1 | ofile, err := ioutil.TempFile(intermediateTempDir, "mr-*") |
总结
首先一定要先理解原理,结合课程多读几遍论文,如果没有理解原理,是不可能正确实现的。然后就是一定要自己亲自动手去实现,当你在实现的时候,你会发现有很多工程上的细节问题需要解决。解决问题的过程也是挑战自己的过程,当遇到问题时,应该更兴奋,多思考,多分析,多总结,因为这个时候更能够提升你的专业技能,enjoy it!
参考资料
[1] MapReduce: Simplified Data Processing on Large Clusters
[2] 6.824 Schedule: Spring 2022